Lab researchers explore ‘learn-by-calibration’ approach to deep learning to accurately emulate scientific process
 (Download Image)
(Download Image)
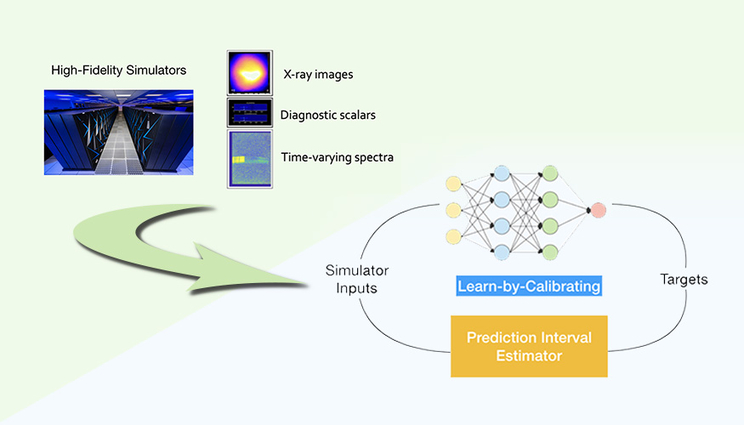
An LLNL team has developed a “Learn-by-Calibrating” method for creating powerful scientific emulators that could be used as proxies for far more computationally intensive simulators. Researchers found the approach results in high-quality predictive models that are closer to real-world data and better calibrated than previous state-of-the-art methods. Illustration courtesy of Jayaraman Thiagarajan/LLNL.
Lawrence Livermore National Laboratory (LLNL) computer scientists have developed a new deep learning approach to designing emulators for scientific processes that is more accurate and efficient than existing methods.
In a paper published by Nature Communications, an LLNL team describes a “Learn-by-Calibrating” (LbC) method for creating powerful scientific emulators that could be used as proxies for far more computationally intensive simulators. While it has become common to use deep neural networks to model scientific data, an often overlooked, yet important, problem is choosing the appropriate loss function — measuring the discrepancy between true simulations and a model’s predictions — to produce the best emulator, researchers said. The article was among those featured in the journal’s special AI and machine learning “Focus” collection on Jan. 26, designating it as one that editors found of particular interest or importance.
The LbC approach is based on interval calibration, which has been used traditionally for evaluating uncertainty estimators, as a training objective to build deep neural networks. Through this novel learning strategy, LbC can effectively recover the inherent noise in data without the need for users to pick a loss function, according to the team.
Applying the LbC technique to various science and engineering benchmark problems, the researchers found the approach results in high-quality predictive models that are closer to real-world data and better calibrated than previous state-of-the-art methods. By demonstrating the technique on scenarios with varying data types and dimensionality, including a reservoir modeling simulation code and inertial confinement fusion (ICF) experiments, the team showed it could be broadly applicable to a range of scientific workflows and integrated with existing tools to simplify subsequent analysis.
“This is an extremely easy-to-use principle that can be added as the loss function for any neural network that we currently use, and make the emulators significantly more accurate,” said lead author Jay Thiagarajan. “We considered different types of scientific data — each of these data have completely different assumptions, but LbC could automatically adapt to those use cases. We are using the same exact algorithm to approximate the underlying scientific process in all these problems, and it consistently produces much better results.”
While there has been a surge in using machine learning to build data-driven emulators, the field has lacked an effective method for determining how closely the predictive models reflect physical reality, Thiagarajan explained. In the latest paper, the LLNL team proposes using calibration-driven training to enable models to capture the inherent data characteristics without making assumptions on data distribution, saving time and effort and improving efficiency.
“Learn-by-Calibrating is an approach that eliminates the pain of having to come up with specific loss functions for every problem,” Thiagarajan said. “It automatically can handle both symmetric and asymmetric noise models and can provide robustness to ‘rare’ outlying data. The other interesting thing is that because we are able to better model the observed data, compared with the standard loss functions people use, we are able to use a smaller neural network with reduced parameters to produce the same result as existing methods.”
In the study, the team applied the approach to a variety of scientific and engineering processes: predicting a superconductor’s critical temperature, estimating the noise of an airfoil in aeronautical systems and the compressive strength of concrete, approximating a decentralized smart grid control simulation, mimicking the clinical scoring process from biomedical measurements in Parkinson patients and emulating a one-dimensional simulator for ICF experiments. The researchers found the LbC approach produced better emulators across the board, with significantly improved generalization than the most common techniques in use today, even among scenarios with small datasets.
“It’s very challenging for emulators to accurately capture the underlying physical processes when they are only given access to the simulation codes in the form of input/output pairs, often resulting in subpar predictive capabilities. With the use of interval calibration, LbC goes one step further during training than simply to match the outputs of the simulator,” said co-author and LLNL computer scientist Rushil Anirudh. “When measuring the quality of emulators with mean squared error (MSE), LbC produces better quality models than the ones that have been explicitly trained using MSE, which is a sign that LbC is indeed able to go behind the curtain to capture some essence of the physical process that governs the actual numerical simulator.”
LLNL scientists said the “plug-and-play” approach could prove valuable, not just for ICF reactions, but with a host of Laboratory applications.
“The Lab’s most critical and high-consequence missions need AI methods that can both improve predictions and precisely quantify the uncertainty in those predictions,” said principal investigator and Cognitive Simulation Initiative Director Brian Spears. “LbC is literally tailor-made to do this, allowing it to tackle key problems in ICF, weapons, predictive biology, additive manufacturing and much more.”
Thiagarajan said the team’s immediate next steps are to integrate the approach into the Lab’s scientific workflows and leverage these higher fidelity emulators to solve other challenging design optimization problems.
The work was funded by the Laboratory Directed Research and Development program.
Co-authors included LLNL researchers Bindya Venkatesh, Peer-Timo Bremer, Jim Gaffney and Gemma Anderson.
Contact
 Jeremy Thomas
Jeremy Thomas
[email protected]
(925) 422-5539
Related Links
"Designing accurate emulators for scientific processes using calibration-driven deep models"Tags
HPC, Simulation, and Data ScienceMachine learning
ASC
Earth and Atmospheric Science
Atmospheric, Earth, and Energy
Computing
Engineering
Physical and Life Sciences
Featured Articles





