Conference papers highlight importance of data security to machine learning
 (Download Image)
(Download Image)
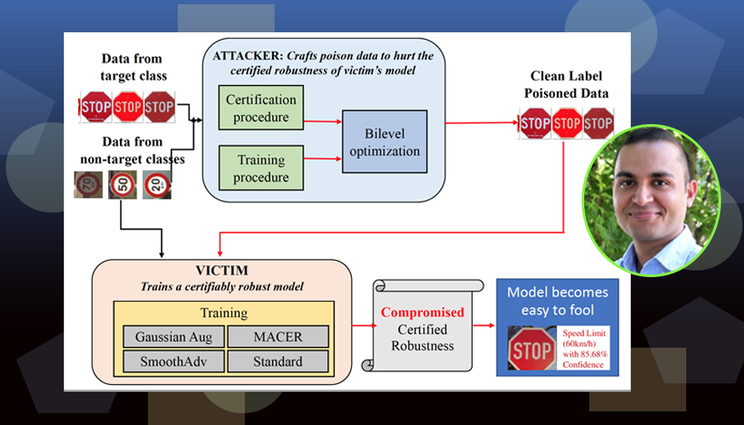
In a paper published by the upcoming 2021 Conference on Computer Vision and Pattern Recognition, Lawrence Livermore National Laboratory computer scientist Bhavya Kailkhura and co-authors present a previously unknown vulnerability of robust machine learning models to imperceptible “data poisoning.” The research is part of an LLNL effort to develop foolproof artificial intelligence and machine learning systems.
The 2021 Conference on Computer Vision and Pattern Recognition, the premier conference of its kind, will feature two papers co-authored by a Lawrence Livermore National Laboratory (LLNL) researcher targeted at improving the understanding of robust machine learning models.
Both papers include contributions from LLNL computer scientist Bhavya Kailkhura and examine the importance of data in building models, part of a Lab effort to develop foolproof artificial intelligence and machine learning systems. The first paper focuses on “poisoning” attacks to data that malicious hackers or adversaries might use to trick artificial intelligence into making mistakes, such as manipulating facial recognition systems to commit fraud or causing autonomous drones to crash.
The team, which includes co-authors from Tulane University and IBM Research, highlighted a previously unknown vulnerability of robust machine learning models to imperceptible data poisoning that severely weakens their certified robustness guarantees. Researchers concluded the study suggests that proper data curation is a crucial factor in creating highly robust models.
“Data should be considered a first-class citizen in a machine learning workflow,” Kailkhura said. “In the past, the sole focus of the robustness community has been on coming up with better training algorithms and models. Here we are suggesting that we have missed the most important piece in the robust machine learning puzzle, and that is the training data quality. In this paper, for the first time we are showing that an adversary can actually devise an extremely hard-to-detect attack on your training data that can fool even state-of-the-art robust models. If an adversary can do this, any model-related advancements we have made in the last several years that guarantee better robustness would be useless.”
Unlike other types of poisoning attacks that reduce the accuracy of the models on a small set of target points, the team was able to make undetectable but devastating distortions in training data and reduce the average certified accuracy (ACA) of an entire dataset target class to zero in several cases. They showed the approach is effective even when the victim trains the models using state-of-the-art methods shown to improve robustness, such as randomized smoothing.
Funded under Kailkhura’s Laboratory Directed Research and Development (LDRD) project to design foolproof machine learning systems, the work impacts national security and mission-critical applications where researchers need to be certain that models will make correct predictions, Kailkhura said. By pointing out a previously unrecognized threat, Kailkhura said he hopes the paper exposes flaws in supposed robust models and will leverage the power of the machine learning community to build models that can detect and withstand such test-time attacks.
“It is going to be extremely difficult to solve the problem by a single team and come up with a model that is robust to these attacks we’ve identified,” Kailkhura said. “This is where the power of collaboration and open science comes into the picture. We are asking for help from the community by publishing these results, and we are seeking ideas and thinking about models that cannot be fooled. What we want to come up with is not yet another robustness heuristic but a foolproof system, so even if an adversary knows about the system, there is nothing they can do.”
Kailkhura said because the changes were so minute that a human user cannot notice, it may take an algorithm to tell the difference between clean and poisoned data. That kind of algorithm is one long-term objective of the research described in the second paper, in which Kailkhura and co-authors from the University of Virginia, the University of Illinois Urbana-Champaign, ETH Zurich and other institutions examined approaches to evaluating data importance.
“Understanding the value of a subset of training examples is a fundamental problem in machine learning that could have profound impact on a range of applications including data valuation, interpretability, data acquisition etc.” Kailkhura said. “For example, data labeling is very expensive, so the question is can we make the process better by only showing a scientist samples what the machine learning model thinks are important? If you want to apply this machine learning model on experiments, how do you choose the samples you believe are most representative of the true phenomena captured by these experiments? If one can do data importance evaluation correctly, all of these problems can be solved.”
Since training massive amounts of models isn’t feasible, computer scientists have turned to mathematical techniques that can tell researchers which data points are most important to collect or analyze, Kailkhura explained. A principled approach is based on “Shapley values” — a concept from game theory that calculates the average marginal contribution from a feature to the model’s prediction, considering all possible combinations.
The downside of the Shapley value approach is that it is extremely computationally expensive and cannot be applied to large models or datasets, such as those used at LLNL, Kailkhura said. The solution is approximation — instead of quantifying the value of data in the original model, researchers use a simplified model so the Shapley value can be calculated more efficiently.
In the paper, the team compared common approximation methods (or heuristics), finding that the approximated Shapley value approach could, in fact, provide correct data quality evaluation at scale. They applied the method to five machine learning tasks common in science: noisy label detection, watermark removal, data summarization, active data acquisition and domain adaptation.
The researchers found the approximation approach could effectively rank data points according to importance and accurately identify which samples were noisy, choose which data samples were most important to acquire or quantify and determine which samples could train models that will do well on the same domain.
“What was not known before is how this approximation effects performance,” Kailkhura said. “We found the approximations we have considered can achieve scalability without compromising utility, which is correctly classifying the quality of your data. This is all about theoretically showing it is possible to do accurate data quality evaluation in a scalable manner.”
The team concluded that Shapley-based methods could outperform “leave-one-out” cross validation methods in both run time and experimental performance. Most notably, they determined a Shapley approach incorporating a surrogate K-nearest neighbor classifier was the most efficient solution and best overall performer. Kailkhura’s LDRD project funded the work.
Kailkhura said the team is working on applying Shapley value-based data quality evaluation methods to “noisy” training data and will soon explore using the approach to identify poisoned data from clean data.
“We’re hoping that we will be able to clean or discard those poisoned samples,” Kailkhura said. “That would imply that, with the certified robustness that state-of-the-art models are achieving, we will be able to achieve them again, but this time in a more realistic setting where data is noisy. If I know which samples are poisoned, I can delete those samples from my training data.”
Co-authors on the data poisoning paper included Akshay Mehra and Jihun Hamm of Tulane University and Pin-Yu Chen of IBM Research. Co-authors on the data evaluation paper included Ruoxi Jia of Virginia Tech University, Fan Wu and Bo Li of University of Illinois Urbana-Champaign, Xuehui Sun of Shanghai Jiao Tong University, Jiacen Xu of the University of California, Irvine, David Dao and Ce Zhang of ETH Zurich and Dawn Song of the University of California, Berkeley.
Contact
 Jeremy Thomas
Jeremy Thomas
[email protected]
(925) 422-5539
Related Links
"How Robust are Randomized Smoothing based Defenses to Data Poisoning?"""Scalability vs. Utility: Do We Have to Sacrifice One for the Other in Data Importance Quantification?" accepted at CVPR 2021"
Tags
HPC, Simulation, and Data ScienceComputing
Engineering
Featured Articles





