Soybean: the first complete legume sequence
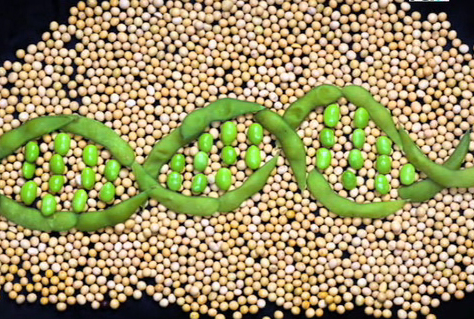
Soybean, one of the most important global sources of protein and oil, is now the first legume species with a published complete draft genome sequence. The sequence and its analysis appear in the Jan. 14 edition of the journal, Nature .
The research team comprised 18 institutions, including the Department of Energy Joint Genome Institute (DOE JGI), the Department of Agriculture-Agricultural Research Service (USDA-ARS), Purdue University and the University of North Carolina at Charlotte. The DOE, National Science Foundation, USDA and the United Soybean Board supported the research.
The soybean genomes billion-plus nucleotides afford scientists a better understanding of the plant's capacity to turn sunlight, carbon dioxide, nitrogen and water, into concentrated energy, protein and nutrients for human and animal use, said Anna Palmisano, DOE associate director of Science for Biological and Environmental Research. This opens the door to crop improvements that are sorely needed for energy production, sustainable human and animal food production and a healthy environmental balance in agriculture worldwide.
With the soybean genetic code now determined, the research community has access to a key reference for more than 20,000 legume species and can explore the extraordinary evolutionary innovation of nitrogen-fixing symbiosis that is so critically important to successful agricultural crop rotation strategies.
Jeremy Schmutz, the study's first author and a DOE JGI scientist at the HudsonAlpha Institute for Biotechnology in Alabama, said that the soybean sequencing was the largest plant project done to date at the DOE Joint Genome Institute. It also happens to be the largest plant that's ever been sequenced by the whole genome shotgun strategy, where it is broken apart and reassembled like a huge puzzle, he said. Of the more than 20 other plant genomes taken on by the DOE JGI, those already sequenced include the black cottonwood (poplar) tree and the grain sorghum, both targeted because of their promise as biomass feedstocks for biofuels production.
"This is a milestone for soybean research and promises to usher in a new era in soybean agronomic improvement," said co-author Gary Stacey, director, Center for Sustainable Energy and associate director and National Center for Soybean Biotechnology, University of Missouri. "The genome provides a parts list of what it takes to make a soybean plant and, more importantly, helps to identify those genes that are essential for such important agronomic traits as protein and oil content."
From the sequence analysis, Stacey said that he and his colleagues have identified more than 46,000 genes of which 1,110 are involved in lipid metabolism. These genes and their associated pathways are the building blocks for soybean oil content and represent targets that can be modified to bolster output and lead to the increase of the use of soybean oil for biodiesel production.
While biodiesel from soybean oil represents a cleaner, renewable alternative to fossil fuels with desirable properties as a liquid transportation fuel, there simply is not enough oil produced by the plant to be a competitive gasoline on a gallons-of-fuel yield per acre. The availability of the soybean genome may provide some key solutions. "We can now zero in on the control points governing carbon flow towards protein and oil," said Tom Clemente, professor, Center for Biotechnology, Center for Plant Science Innovation at the University of Nebraska, Lincoln. "With the combination of informatics, biochemistry and genetics, we can target the development of a soybean with greater than 40 percent oil content."
The availability of the soybean genome sequence has accelerated other soybean trait discovery efforts as well. For example, researchers have used the sequence to zero in on a mutation that can be used to select for a line that has lower levels of the sugar stachyose, which will improve the ability of animals and humans to digest soybeans.
In another effort, by comparing the genomes of soybean and corn, a single-base pair mutation was found that causes a reduction in phytate production in soybean. Phytate is the form in which phosphorous is stored in plant tissue. Because phytate is not absorbed by the animals that eat the feed, the unabsorbed phytate passes through the gastrointestinal tract, elevating the amount of phosphorus in the manure. Limiting phytate production in the soybean could reduce a major environmental runoff contaminant from swine and poultry waste.
Of additional importance for soybean farmers is that the genome sequence has provided access to the first resistance gene for the devastating disease Asian Soybean Rust (ASR). In countries where ASR is well established, soybean yield losses due to the disease can be as high as 80 percent.
A video of Schmutz discussing the soybean genome project can be viewed at the DOE JGI's SciVee Channel.


