Model for COVID-19 drug discovery a Gordon Bell finalist
 (Download Image)
(Download Image)
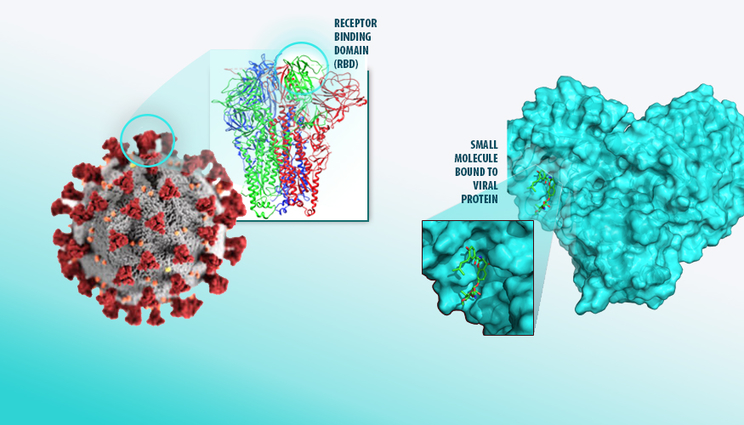
Using Sierra, the world’s third fastest supercomputer, LLNL scientists produced a more accurate and efficient generative model to enable COVID-19 researchers to produce novel compounds that could possibly treat the disease. The team trained the model on an unprecedented 1.6 billion small molecule compounds and one million additional promising compounds for COVID-19, reducing the model training time from one day to just 23 minutes.
A machine learning model developed by a team of Lawrence Livermore National Laboratory (LLNL) scientists to aid in COVID-19 drug discovery efforts is a finalist for the Gordon Bell Special Prize for High Performance Computing-Based COVID-19 Research.
Using Sierra, the world’s third fastest supercomputer, LLNL scientists created a more accurate and efficient generative model to enable COVID-19 researchers to produce novel compounds that could possibly treat the disease. The team trained the model on an unprecedented 1.6 billion small molecule compounds and one million additional promising compounds for COVID-19, reducing the model training time from one day to just 23 minutes.
“This capability will have a dramatic impact on drug discovery,” said paper co-author and LLNL computer scientist Ian Karlin. “This ability to quickly create high-quality machine learning models changes the time-to-insight from a compute-limited issue to a human-limited one.”
Since the early days of the pandemic, LLNL scientists have been using machine learning to discover countermeasures capable of binding to protein sites in the SARS-CoV-2 virus that causes COVID-19. Lab researchers plan to incorporate the improved generative model into the small molecule drug design loop to create more diverse and potentially more effective drug compounds to synthesize for experimental testing, a critical factor in the race to find new COVID-19 therapeutics.
“The goal of this project is to generate new molecules within a large space based on promising ones from the docking, binding and molecular dynamics work, but make them a little different so COVID-19 researchers can optimize their designs,” said paper co-author Felice Lightstone, who heads the COVID-19 small molecule work.
New for this year, the special Gordon Bell Prize for COVID-19 Research will be announced on Nov. 19 at the virtual 2020 Supercomputing Conference (SC20). Awarded by the Association for Computing Machinery, the prize recognizes the contributions of HPC and parallel computing to the understanding of the COVID-19 pandemic. The four finalists were selected based on performance and innovation in their computational methods, as well their contributions toward understanding the nature, spread and/or treatment of the disease. The winning team will receive a $10,000 award.
LLNL scientists said their multi-level parallel training approach performed well across multiple scales, including the entire 125 petaflop IBM/NVIDIA supercomputer Sierra with up to 97.7 percent efficiency. Using the Livermore Big Artificial Neural Network Toolkit (LBANN), which enables deep learning research at previously unobtainable scales, the team trained a novel Wasserstein autoencoder on a 1.613 billion molecule training set and a 1.01 million molecule test set, nearly an order of magnitude more chemical compounds than any other work reported to date.
“We are taking the decades of experience that the national labs have and bringing it to bear to enable both combinations of strong and weak scaling for this kind of machine learning problem,” said principal investigator Brian Van Essen. “This has the potential to help transform drug discovery into a more computationally driven process.”
Utilizing mixed-precision training, the team was able to achieve 17.1 percent of half-precision machine peak using tensor cores. While scaling the model to all of Sierra was a “significant challenge,” with even modest computing resources, scientists said they could train or retrain dozens of new models in under an hour, even as new compounds are generated, to create an automated “self-learning design loop” to accelerate drug discovery.
As researchers find more promising compounds for COVID-19 and new pathogens emerge, researchers will need to retrain the model for new protein targets and refine the chemical search. With the number of drug-like molecules estimated at 1060, the ability to rapidly train and retrain machine learning models at such a large scale is “incredibly revolutionary” for drug discovery, Van Essen said.
Using the model, COVID-19 researchers expect to be able to select promising compounds, project them into the model’s latent space and optimize their chemical properties to create similar but novel compounds that can be further evaluated through experimental testing.
“A generative model supports efficient exploration of novel parts of makeable chemical space and should improve our chances of finding small molecules to act as a countermeasure for a novel pathogen,” said computer scientist Jonathan Allen. “We’re looking at being able to propose new compounds that are computationally predicted to meet multiple pharmacologically based design criteria in a single evaluation step. This contrasts with the traditional approach of serially optimizing and experimentally testing each property separately, which greatly lengthens drug discovery and development times.”
To train the model, LLNL computer scientist Sam Ade Jacobs and colleagues designed and implemented a character-based Wasserstein autoencoder (cWAE). In contrast to the state-of-the-art (baseline) molecular generative models like variational autoencoders and junction-tree variational autoencoders, cWAE enforces a stronger constraint during training. These constraints lead to better continuous latent space, and therefore better reconstruction and sampling of molecules from latent space.
“For targeted drug design for COVID-19, you need a generative model that preserves reconstruction while increasing diversity of variations in the latent space,” Jacobs said. “We found the Wasserstein autoencoder is best suited for this task.”
Besides increased speed, researchers demonstrated the approach was more accurate than the variational autoencoder, providing more robust compound reconstructions and an order of magnitude improvement in Average Tanimoto Distance, a metric describing the similarity between the compounds run through the model and their original input compounds.
Researchers said while the results are promising, they want to improve the scaling and train using more types of models. Their next step is to incorporate the fully trained model into the drug design loop so COVID-19 scientists can use it to evaluate a more diverse set of compounds, predict more valid chemicals and exert more control over specialization of new compounds.
The team also wants to make the model more automated and improve the efficiency of the overall general drug discovery loop through the Accelerating Therapeutic Opportunities in Medicine (ATOM) consortium, which will help improve rapid response to future viruses. Scientists also will look at training on other architectures and use higher order optimization methods to dramatically improve the model’s quality and speed.
The model is being promoted to other Department of Energy (DOE) national laboratories and is being investigated by the Exascale Computing Project’s (ECP) ExaLearn, a co-design center for Exascale Machine Learning Technologies, and the CANDLE (Cancer Distributed Learning Environment) project led by DOE, ECP and the National Cancer Institute. It also has drawn interest from industry.
Active funding for the research was provided by ExaLearn and ATOM projects. Prior funding for core investments in LBANN includes the Laboratory Directed Research and Development program as well as the ECP CANDLE project. The LLNL Advanced Simulation and Computing program provided funding for ATOM, and staff support and computer time for the effort. Co-authors include Tim Moon, Kevin McLoughlin, Derek Jones, David Hysom, Dong Ahn, John Gyllenhaal and Pythagoras Watson.
Van Essen will be presenting the paper during SC20 on Nov. 19 at 10 a.m. EST.
Find out more on the Gordon Bell Special Prize for High Performance Computing-Based COVID-19 Research.
For more on LLNL’s COVID-19 research, visit the web.
Contact
 Jeremy Thomas
Jeremy Thomas
[email protected]
(925) 422-5539
Related Links
"Lab antibody, anti-viral research aids COVID-19 response""ACM Gordon Bell Special Prize for High Performance Computing-Based COVID-19 Research"
LLNL COVID-19 Research and Response
Tags
HPC, Simulation, and Data ScienceSupercomputing
ASC
Bioscience and Bioengineering
Biosciences and Biotechnology
Computing
Engineering
Physical and Life Sciences
Featured Articles





